介绍
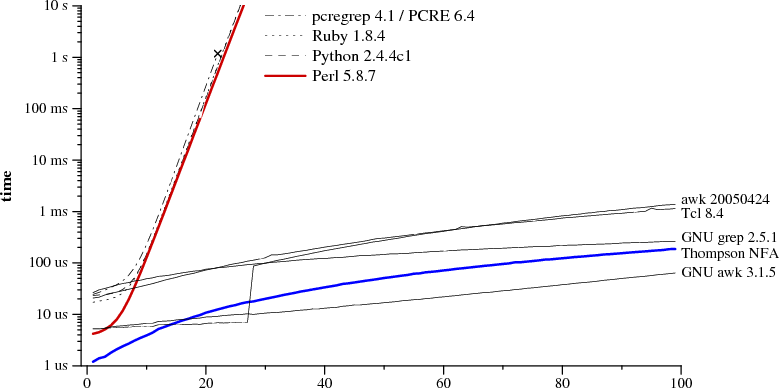
这个篇文章是对我的一个基本功能的正则引擎的实现过程的大致介绍与讨论,实际上在之前的文章中我已经对正则引擎的实现有所涉及,当时是翻译了有关Thompson NFA的文章,文章及其附带的源代码中已经对如何实现一个简单的正则引擎有了详细的说明,但是该文章对正则引擎的介绍并不深入,同时实现方式也过于简单化,虽然最终的结果是高效可靠的,但是这个实现不便于扩展,同时支持的功能也比较有限,因此在这一次的实现中,我采用了更加主流的方法,这样支持了更多的功能,同时也易于扩展。该项目使用的语言为C++,完整项目请移步regexEngine2。
引擎功能介绍
下面简单地介绍一下这一次的正则的一些功能(并联串联功能不再赘述):
1.’*‘:零个或多个
2.’+’:一个或多个
3.’?’:零个或一个
4.’ . ‘:匹配任意一个字符
5.{a}:重复a次;{a,b}:重复次数大于等于a小于等于b;{a,}:重复次数大于等于a
6.[m-n]:匹配范围内的字符(例如:[a-g]等价于a|b|c|d|e|f|g等价于[abcdefg])
7.[^m-n]:匹配不是范围内的字符
同时还加入了一些特殊的转义字符:
1.\d:等价于[0-9]
2.\D:等价于[^0-9]
3.\s:等价于[\t\n\r\f]
4.\S:等价于[^\t\n\r\f]
5.\w:等价于[a-zA-Z0-9_]
6.\W:等价于[^a-zA-Z0-9_]